Language Models can Solve Computer Tasks
Demonstrations on MiniWoB++ Tasks
We have evaluated our LLM computer agent on a wide range of tasks in MiniWoB++ benchmark. Every task contains a natural language prompt in yellow. The agent then uses keyboard strokes and mouse clicks to accomplish the task.
terminal
email-inbox
search-engine
login-user
Abstract
Agents capable of carrying out general tasks on a computer can improve efficiency and productivity by automating repetitive tasks and assisting in complex problem-solving. Ideally, such agents should be able to solve new computer tasks presented to them through natural language commands. However, previous approaches to this problem require large amounts of expert demonstrations and task-specific reward functions, both of which are impractical for new tasks. In this work, we show that a pre-trained large language model (LLM) agent can execute computer tasks guided by natural language using a simple prompting scheme where the agent recursively criticizes and improves its output (RCI). The RCI approach significantly outperforms existing LLM methods for automating computer tasks and surpasses supervised learning (SL) and reinforcement learning (RL) approaches on the MiniWoB++ benchmark. RCI is competitive with the state-of-the-art SL+RL method, using only a handful of demonstrations per task rather than tens of thousands, and without a task-specific reward function. Furthermore, we demonstrate RCI prompting's effectiveness in enhancing LLMs' reasoning abilities on a suite of natural language reasoning tasks, outperforming chain of thought (CoT) prompting. We find that RCI combined with CoT performs better than either separately.
RCI prompting
We introduce a simple reasoning architecture called RCI prompting, where we prompt LLMs to find problems in their output and improve the output based on what they find. This architecture is designed to further enhance the reasoning ability of LLMs by inserting a critique step before generating the final answer. We define two approaches for achieving RCI: explicit RCI and implicit RCI. Explicit RCI includes the critique in the prompt to generate improved output and implicit RCI updates the previous output directly without sampling a critique explicitly. The following displays an illustration of explicit RCI on GSM8K data.
RCI for Computer Tasks
Below is an execution trace of the agent performing terminal tasks with RCI prompting. The language model generates a step-by-step plan for the high-level task described in natural language, which in this case involves using the terminal to delete a file ending with ".rb". We then run an explicit RCI on this plan, where we sample an improved plan based on the critique and the previous plan, resulting in an improvement in the task-grounding of the plan. For each step, we first sample the task-grounded action that follows the improved plan, and then the implicit RCI updates the task-grounded actions sequentially to provide state-grounding and agent-grounding. Finally, the agent-grounded action is executed on the environment. Prompts are highlighted in green.
Results on Reasoning Tasks
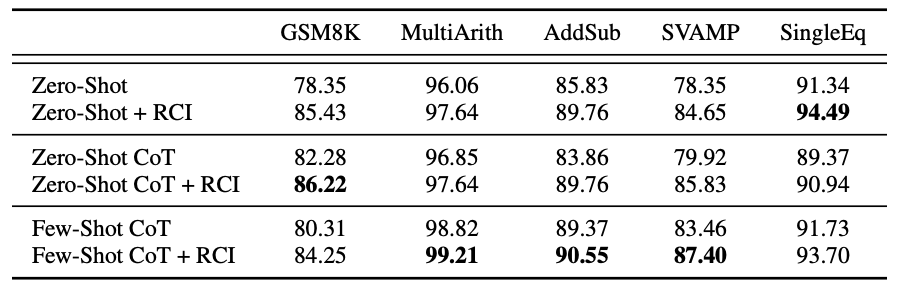
In our study, we have proven the efficacy of using RCI prompts to enhance the reasoning abilities of LLMs on various reasoning benchmarks. Our findings indicate that RCI prompts outperform zero-shot prompts in solving reasoning tasks. Notably, RCI prompting even yields significant improvements in scores for two arithmetic reasoning tasks (SingleEq and AddSub) that do not necessitate multi-step reasoning.

We also compare RCI to Chain-of-Thought (CoT) prompting, a state-of-the-art method recognized for its effectiveness in reasoning tasks. Interestingly, we discovered a noteworthy collaborative impact between RCI prompting and the two CoT baselines.
Results on MiniWoB++ tasks
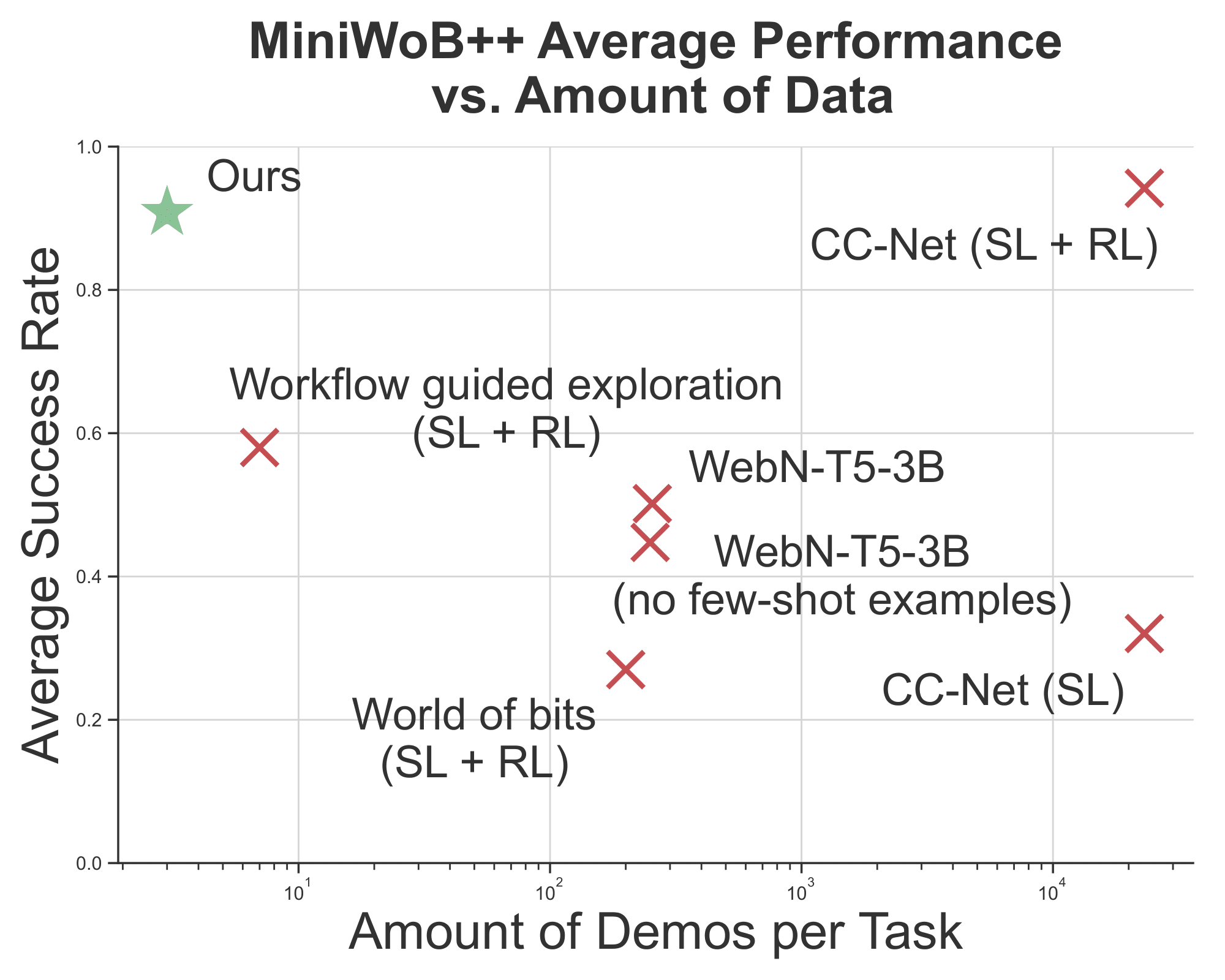
The figure presented below provides an overview of the mean success rates attained by our agent and the baseline models across the MiniWoB++ benchmark. Our agent surpasses the performance of the state-of-the-art approaches, including Supervised Learning (SL), Reinforcement Learning (RL), and LLM-based methods. Among the baseline models, our approach achieves the second-highest score.
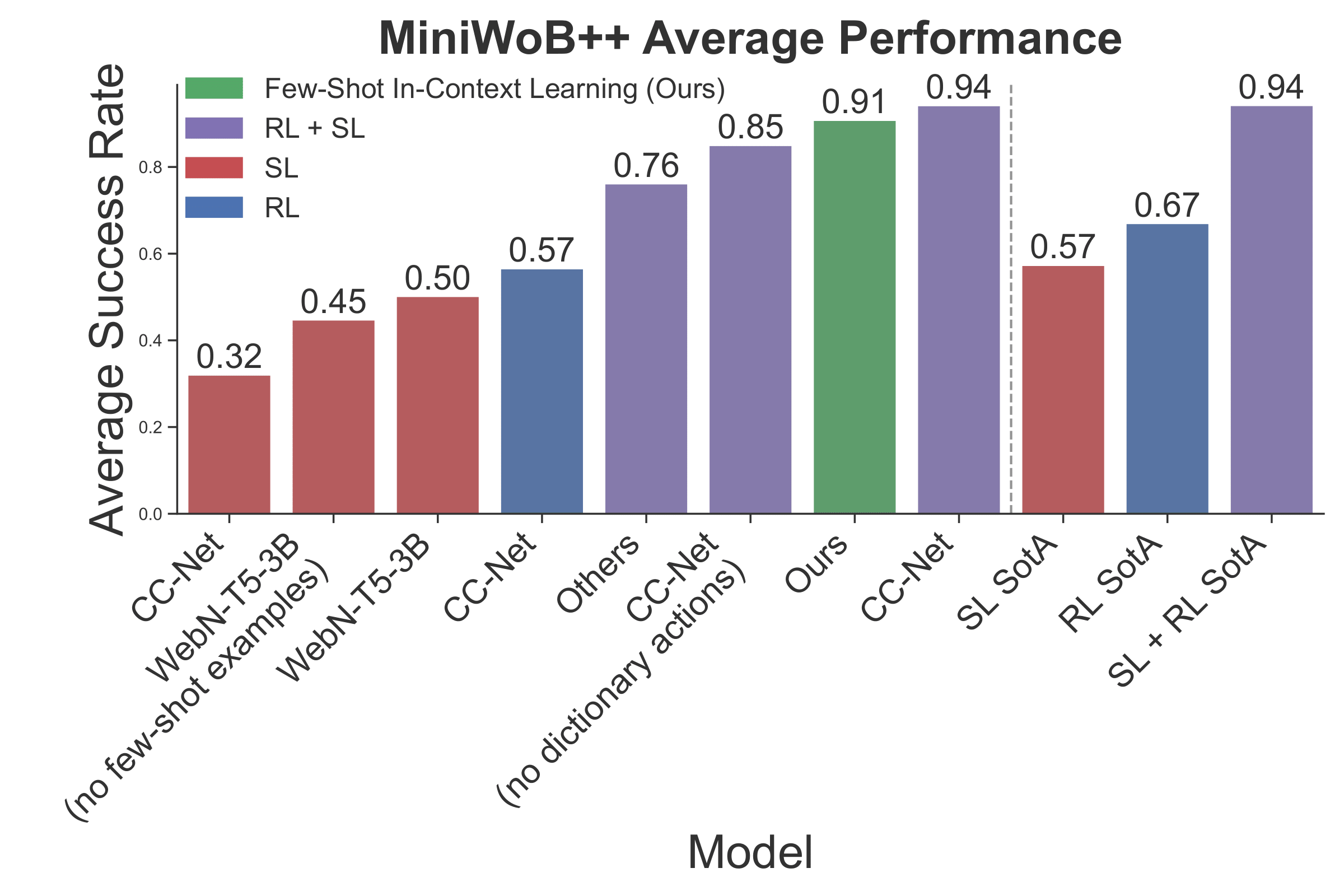
The outcomes of our study indicate that our agent surpassed the baselines, with the exception of CC-Net (SL + RL) which uses dictionary-based typing actions. It accomplished this feat while using 120 times fewer samples than WebN-T5-3B and 11,000 times fewer samples than CC-Net. Due to the difficulties associated with obtaining expert demonstrations and defining reward functions for computer tasks, our research highlights the potential of leveraging LLMs for general computer tasks.